Deploy Kubernetes Clusters in OpenStack within minutes with Magnum

Now that we have set up our cool and high available OpenStack cloud, it is time to try out the various services that you can provide to your end users in OpenStack. Today we will take a look at Magnum. From the official OpenStack Magnum website:
Magnum is an OpenStack API service developed by the OpenStack Containers Team making container orchestration engines (COE) such as Docker Swarm and Kubernetes available as first class resources in OpenStack.
Simply spoken it will automate the deployment of Kubernetes (K8s) in your OpenStack cloud. I think Docker Swarm is hardly used anywhere and if I remember correctly it is or will be deprecated soon in Magnum. The first time I used Magnum was over two years ago and back then it was kind of trial and error to get a working cluster deployed. Especially when using Magnum in conjunction with Octavia load balancer. To be honest my latest journey with Magnum was not any different. As usual it is the documentation that is not 100% up to date. I don't blame the developers or community for this. If you imagine how many different parts are involved just in Magnum and all have to play together nicely it is no wonder that you will not find a 100% working and accurate documentation all the time. The docs might have been just fine a few months ago but since then the various parts in K8s like CSI, CRI and so on have been updated and you have to make sure that you always use the right versions that fit together. Just yesterday I had given up on deploying what is said to be the default version of K8s in the Yoga release of Magnum which is 1.23.3.
Foreword (Or the long story of my Trial and Error with Magnum)
So before we dive into how you can deploy Magnum, create a template and finally deploy clusters, I would like to give you an idea of what is currently not working. Let's start by looking at the supported Fedora CoreOS and K8s versions.
Supported versions
The supported (tested) versions of Kubernetes and Operating Systems are:
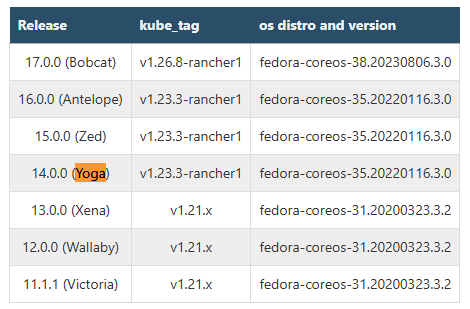
I have copied the table from the official Magnum User Guide.
I would have expected this to work out of the box, but the truth is, it doesn't. After several attempts I just gave up on v1.23.3 and instead tried deploying a much older K8s version v1.21.11. This worked just fine with a few minor tweaks. The problem with the default version of v1.23.3 is, that this is not compatible with the old CSI container versions that ship with Magnum. After the deployment you will see a healthy cluster, but if we look closer, we will se this:
kubectl get pods -A
...
kube-system csi-cinder-controllerplugin-0 4/5 CrashLoopBackOff 6
(4m54s ago) 14mSo you will end up with a somewhat working cluster, but you will not be able to create and bind persistent volumes to your pods. I'm sure that you can fix this with some effort after the cluster has been deployed but that is not the experience you want to give to your end users. After googling I found others facing the same problem and the suggestion was to change the version of the csi-snapshotter container by simply adding the label "csi_snapshotter_tag = v4.0.0". And yes this fixes the issue with the crashloop container, but it will still not work since the other dependend Kubernetes CSI Sidecar Containers versions also need to be adjusted. At least that is what I conclude since I couldn't successfully bind a PV to a pod. The funny thing is that the official documentation actually states that version 4.2.1 should be the default for Yoga:
csi_snapshotter_tag
This label allows users to override the default container tag for CSI snapshotter. For additional tags, refer to CSI snapshotter page. Ussuri-default: v1.2.2 Yoga-default: v4.2.1
It doesn't seem to be the case or I completely screwed this up but I don't know how. The cool thing about Opensource is you can look in the code yourself and see what is going on. So I cloned the Gitrepo and did a grep on 4.2 and found nothing. So I don't think that I did something wrong. But still It would be great if that could be 100% clarified.
By default the following CSI Sidecar Containers will be deployed:
(yoga) [vagrant@seed ~]$ kubectl describe pod -n kube-system csi-cinder-controllerplugin-0 | grep Image:
Image: 192.168.5.10:4000/csi-attacher:v2.0.0
Image: 192.168.5.10:4000/csi-provisioner:v1.4.0
Image: 192.168.5.10:4000/csi-snapshotter:v1.2.2
Image: 192.168.5.10:4000/csi-resizer:v0.3.0
Image: 192.168.5.10:4000/cinder-csi-plugin:v1.18.0These are working just fine with the older v1.21.11 K8s release, but not with the newer default K8s release of v1.23.3 that is deployed by Magnum. If you try containerd by specifying the label:
container_runtime: containerd
You will also end up with a lot of containers not working. Probably due to a problem with flannel:
kubectl get events -A | grep -v Normal
....
kube-system 11s Warning FailedCreatePodSandBox pod/npd-69rnl (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "53fd192386d737374fb4f7a3a99aa0a5b83c923a58a45c994f54f8f3b19d7548": failed to find plugin "flannel" in path [/usr/libexec/cni/]So you see it is really tricky to deploy a working cluster since there are so many points that need tweaking. It would be highly appreciated if it would be possible to just deploy a working K8s cluster out of the box. But no worries I managed to get it working. If you are interested keep reading.
Install Magnum
If you followed and used my Terraform manifest from my last blog post on how to create a single or multinode OpenStack cluster on top of VMware ESXi, you already have a working Magnum installation. If not, you can pretty much just follow the official Kolla-Ansible Magnum guide. This is working very well. You simply enable Magnum in /etc/kolla/globals.yml:
enable_magnum: "yes"
Additionally you should add the following config file for Magnum if you want to use the auto-scaler or auto-healer. But keep in mind that this exposes your cluster to a security vulnerability CVE-2016-7404.
(yoga) [vagrant@seed ~]$ cat /etc/kolla/config/magnum.conf
[trust]
cluster_user_trust = TrueAlso I'm not 100% sure if this is still needed, nor if it is the right way to do, but this was mentioned in the official Magnum User Guide for an older OpenStack release. In the Yoga documentation it just mentions to set parameter "enable_cluster_user_trust: true" in globals.yml. I couldn't find this in my globals.yml file and so I just sticked with the older approach.
To deploy, we run:
kolla-ansible -i multinode deploy -t common,horizon,magnumAfter the deployment we can check that the Magnum services are up:
(yoga) [vagrant@seed ~]$ openstack coe service list
+----+----------------+------------------+-------+----------+-----------------+---------------------------+---------------------------+
| id | host | binary | state | disabled | disabled_reason | created_at | updated_at |
+----+----------------+------------------+-------+----------+-----------------+---------------------------+---------------------------+
| 3 | 192.168.20.141 | magnum-conductor | up | False | None | 2023-02-20T14:45:40+00:00 | 2023-02-25T17:42:35+00:00 |
| 6 | 192.168.20.142 | magnum-conductor | up | False | None | 2023-02-20T14:45:40+00:00 | 2023-02-25T17:42:18+00:00 |
| 9 | 192.168.20.143 | magnum-conductor | up | False | None | 2023-02-20T14:45:40+00:00 | 2023-02-25T17:41:53+00:00 |
+----+----------------+------------------+-------+----------+-----------------+---------------------------+---------------------------+Magnum needs to deploy instances where the Kubernetes Master and Worker Nodes will be deployed. Currently supported is only Fedora CoreOS. So we download and extract the Fedora CoreOS 35 image
curl -k0 https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/35.20220424.3.0/x86_64/fedora-coreos-35.20220424.3.0-openstack.x86_64.qcow2.xz -o fedora-coreos-35.20220424.3.0-openstack.x86_64.qcow2.xz
unxz fedora-coreos-35.20220424.3.0-openstack.x86_64.qcow2.xzand finally upload it to Glance
openstack image create Fedora-CoreOS-35 \
--public \
--disk-format=qcow2 \
--container-format=bare \
--property os_distro='fedora-coreos' \
--file=fedora-coreos-35.20220424.3.0-openstack.x86_64.qcow2This is pretty much it for the installation and configuration of Magnum. Next we will create a template and deploy our first cluster.
Deploy a K8s Cluster
In order to deploy a cluster we must first create a template that describes what image, keypair, networks and so on will be used. I created the following cluster template
openstack coe cluster template create k8s-flan-small-35-1.21.11 \
--image Fedora-CoreOS-35 \
--keypair mykey \
--external-network ext-net \
--dns-nameserver 8.8.8.8 \
--flavor m1.small \
--master-flavor m1.small \
--volume-driver cinder \
--docker-volume-size 10 \
--network-driver flannel \
--docker-storage-driver overlay2 \
--coe kubernetes \
--labels kube_tag=v1.21.11-rancher1,hyperkube_prefix=docker.io/rancher/And now we can deploy our first K8s cluster using this template
openstack coe cluster create --cluster-template k8s-flan-small-35-1.21.11 --keypair mykey --master-count 1 --node-count 1 k8s-01Given that you have enough resources, Magnum will try to create the K8s cluster
(yoga) [vagrant@seed ~]$ openstack coe cluster list
+--------------------------------------+-------------+---------+------------+--------------+--------------------+---------------+
| uuid | name | keypair | node_count | master_count | status | health_status |
+--------------------------------------+-------------+---------+------------+--------------+--------------------+---------------+
| 08902942-2eff-4e35-a667-d1aa09930621 | k8s-01 | mykey | 1 | 1 | CREATE_IN_PROGRESS | None |
+--------------------------------------+-------------+---------+------------+--------------+--------------------+---------------+You will at least require two free Floating IPs and enough resources to spin up two m1.small instances. Magnum will now first deploy a Fedora CoreOS35 instance for creating a K8s master.
(yoga) [vagrant@seed ~]$ openstack server list
+--------------------------------------+-----------------------------------+--------+-----------------------------------+------------------+---------------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-----------------------------------+--------+-----------------------------------+------------------+---------------------+
| 264ddce2-7ccd-42ec-8fdb-551d879230ae | k8s-01-pxe5kz4baxuq-master-0 | ACTIVE | demo-net=10.0.0.41, 192.168.2.136 | Fedora-CoreOS-35 | m1.kubernetes.small |Magnum uses Heat Orchestration for this. So there is a stack that we can watch
openstack stack list --nested -f yamlAfter a few minutes a second instance will be started for the worker node
(yoga) [vagrant@seed ~]$ openstack server list
+--------------------------------------+-----------------------------------+--------+-----------------------------------+------------------+---------------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-----------------------------------+--------+-----------------------------------+------------------+---------------------+
| b504e136-2435-4a04-ba74-d2d23c2c76f3 | k8s-01-pxe5kz4baxuq-node-0 | ACTIVE | demo-net=10.0.0.3, 192.168.2.135 | Fedora-CoreOS-35 | m1.kubernetes.small |
| 264ddce2-7ccd-42ec-8fdb-551d879230ae | k8s-01-pxe5kz4baxuq-master-0 | ACTIVE | demo-net=10.0.0.41, 192.168.2.136 | Fedora-CoreOS-35 | m1.kubernetes.small |In case you still don't see a second node you can ssh directly in the master and check a couple of things. For this we use the user core and our SSH private key that we specified when we created the cluster.
yoga) [vagrant@seed ~]$ ssh core@1192.168.2.136
The authenticity of host '1192.168.2.136 (1192.168.2.136)' can't be established.
ECDSA key fingerprint is SHA256:VZIZuvYcKIBtCcKuTcZrnrdxtmss9g7HetWXT3+p7rk.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '1192.168.2.136' (ECDSA) to the list of known hosts.
Fedora CoreOS 35.20220424.3.0
Tracker: https://github.com/coreos/fedora-coreos-tracker
Discuss: https://discussion.fedoraproject.org/tag/coreos
[core@k8s-01-pxe5kz4baxuq-master-0 ~]$ sudo -i
[root@k8s-01-pxe5kz4baxuq-master-0 ~]# systemctl --failed
UNIT LOAD ACTIVE SUB DESCRIPTION
0 loaded units listed.
[root@k8s-01-pxe5kz4baxuq-master-0 ~]# tail -f /var/log/heat-config/heat-config-script/b4786468-222c-4154-b5ed-00572a829c4f-k8s-01-pxe5kz4baxuq-kube_masters-pwhfrwzeppti-0-n7pbedezplyo-master_config-pexb6c6wcu3a.logThis should give you a clue on why it is stuck or even failing. In my case the etcd service sometimes goes haywire and so I restart it:
[core@k8s-01-pxe5kz4baxuq-master-0 ~]$ sudo -i
[systemd]
Failed Units: 1
etcd.service
[root@k8s-01-pxe5kz4baxuq-master-0 ~]# systemctl restart etcd
[root@k8s-01-pxe5kz4baxuq-master-0 ~]# systemctl --failedThe default timeout is 60 minutes so you have plenty of time to fix things while Heat is trying to deploy the cluster. :) Be patient. On my ESXi host it can take up to 10 minutes for the cluster to be deployed
(yoga) [vagrant@seed ~]$ openstack coe cluster list
+--------------------------------------+-------------+---------+------------+--------------+-----------------+---------------+
| uuid | name | keypair | node_count | master_count | status | health_status |
+--------------------------------------+-------------+---------+------------+--------------+-----------------+---------------+
| 08902942-2eff-4e35-a667-d1aa09930621 | k8s-01 | mykey | 1 | 1 | CREATE_COMPLETE | HEALTHY |
+--------------------------------------+-------------+---------+------------+--------------+-----------------+---------------+
Don't be fooled by the healthy status. You can have a healthy status and still some things inside the cluster are not right. But no worries we will of course check this. So now you might wonder how can I access my cluster and this. is very simple and cool. Just run:
(yoga) [vagrant@seed ~]$ openstack coe cluster config k8s-01
export KUBECONFIG=/home/vagrant/configThis will pull the K8s config file and store it as config in our home dir. In case you already have a config file it will exit with a warning. You can force it to overwrite your file by adding "--force" or even a directory by "--dir". It also tells us. to execute
export KUBECONFIG=/home/vagrant/configSo that kubectl knows where our config is. I quickly installed kubectl using Arkade
curl -sLS https://get.arkade.dev | sudo sh
arkade get kubectl@v1.21.11
export PATH=$PATH:~/.arkade/binCheck the nodes in the cluster
(yoga) [vagrant@seed ~]$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-01-pxe5kz4baxuq-master-0 Ready master 20m v1.21.11 10.0.0.41 192.168.2.136 Fedora CoreOS 35.20220424.3.0 5.17.4-200.fc35.x86_64 docker://20.10.12
k8s-01-pxe5kz4baxuq-node-0 Ready <none> 15m v1.21.11 10.0.0.3 192.168.2.135 Fedora CoreOS 35.20220424.3.0 5.17.4-200.fc35.x86_64 docker://20.10.12
Check the pods
(yoga) [vagrant@seed ~]$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-56ff8559f8-2hvz4 1/1 Running 0 21m
kube-system coredns-56ff8559f8-v8jsk 1/1 Running 0 21m
kube-system csi-cinder-controllerplugin-0 5/5 Running 0 21m
kube-system csi-cinder-nodeplugin-dggz5 2/2 Running 0 21m
kube-system csi-cinder-nodeplugin-hp2b6 2/2 Running 0 17m
kube-system dashboard-metrics-scraper-77db94b5df-flrcb 1/1 Running 0 21m
kube-system k8s-keystone-auth-lpnsf 1/1 Running 0 21m
kube-system kube-dns-autoscaler-66f4c44fc8-wrgrs 1/1 Running 0 21m
kube-system kube-flannel-ds-5ts5l 1/1 Running 0 21m
kube-system kube-flannel-ds-8ctx2 1/1 Running 0 17m
kube-system kubernetes-dashboard-79b66c9777-fkpdb 1/1 Running 0 21m
kube-system magnum-metrics-server-6d74b6b4fb-qjd5c 1/1 Running 0 20m
kube-system npd-j9s8l 1/1 Running 0 16m
kube-system openstack-cloud-controller-manager-m4rtc 1/1 Running 0 21m
Congrats!!! We have deployed a working K8s cluster. Of course the cluster is a very simple cluster at the moment with just a single master and one worker node, but you can even deploy multiple master nodes to make it more resilient. For this we need to Install Octavia Loadbalancer. I will cover this in my next blog post. Stay tuned.
Sources
